
Suppose you were going to translate a sentence out of English into French, and you could only read a word at a time and when you came to the next word you had to forget the one you had just come from. This was essentially the challenge facing AI language models before 2017. That was when a group of researchers at Google released a paper titled Attention Is All You Need, and everything changed.
That paper introduced the Transformer the architecture that has become the workhorse of almost all of the powerful AI language models you have heard of, including ChatGPT, Google Translate, and the AI assistant you may be reading this through at this very moment.
1 The Problem with the Old Way: RNNs
The popular approach to language tasks before the Transformer was a mechanism known as a Recurrent Neural Network, or RNN (also popularly known as LSTM Long Short-Term Memory). The concept behind RNNs is quite simple: read a sentence word by word, and carry a memory of what has already been read as you continue forward. However, there were some fatal flaws in this design.
First, it was slow. Since RNNs operate on each word sequentially, you cannot speed things up by running calculations simultaneously. It is like having 100 math problems to solve but only being allowed to work on one at a time even when there are 100 calculators sitting right in front of you.
Second, long-range memory was poor in RNNs. When a sentence is long and a word towards the end relies on something that was said at the very beginning, the RNN often forgot that earlier context by the time it reached that point. This is also known as the vanishing gradient problem the signal from early words fades out before it reaches the end of the sequence.
This meant that the highest-performing RNN models were hitting a performance ceiling. Something new was needed.
2 Enter the Transformer: Attention Is All You Need
The Transformer discarded recurrence completely. Instead of reading words one after another and building a chain of memory, it looks at all words simultaneously and calculates which words should pay attention to which others hence the name.
The most important innovation is referred to as self-attention (also known as scaled dot-product attention). The intuition here is that when reading the sentence “The animal did not cross the street because it was too tired,” a human reader can immediately realize that “it” refers to the animal, not the street. Self-attention allows the model to do the same thing it measures the relevance of each word to all other words in the sentence at the same time.
Mathematically, the model constructs three things for every word: a Query (what am I looking for?), a Key (what do I have to offer?), and a Value (what information do I actually carry?). By comparing queries and keys across all words, the model produces attention scores that show the extent to which each word influences the understanding of every other word. This is accomplished all at once no waiting, no forgetting.
3 Multi-Head Attention: Looking from Multiple Angles
Multi-head attention is one of the clever tricks the Transformer uses. Rather than performing this attention calculation only once, the model performs it multiple times in parallel, each time with a slightly different learned perspective. Imagine eight different readers, each paying attention to a different aspect of the sentence grammar, meaning, tone, word relationships and then combining all of their insights together.
The original paper employed 8 parallel attention heads. This enabled the model to capture far richer patterns than a single perspective ever could.
4 The Encoder and Decoder
The full Transformer consists of two main components: an encoder and a decoder.
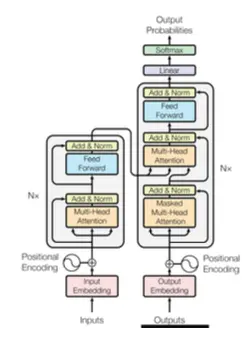
The encoder takes in the input (for example, an English sentence) and builds a deep understanding of it. It applies self-attention so that every word is able to refer to every other word freely. Think of it as a careful reader who absorbs the full meaning of a text before responding.
The decoder produces the output (a French translation) word by word. However, unlike an RNN, it can still look back at everything the encoder has learned. It also contains a special masked self-attention layer that prevents the model from cheating by looking ahead at future words it has not yet generated.
Together, the encoder-decoder architecture is what makes the Transformer so capable at sequence-to-sequence tasks translation, summarization, and question answering.
5 Positional Encoding: Teaching the Model About Order
There is one catch: since the Transformer reads all words at once, it does not automatically know the order in which they appear. Without some sense of position, the phrases “dog bites man” and “man bites dog” would look identical.
The answer is positional encoding a mathematical signal added to the representation of every word that tells the model where in the sequence that word sits. The original paper employed sine and cosine waves of varying frequencies to encode position. It is a small but essential trick that allows the Transformer to understand word order even while processing everything in parallel.
6 Why This Revolutionized AI
The findings were mind-boggling. The original Transformer set a new record on English-to-German translation, surpassing all previous models including those using ensembles of many models working together while being trained in just 3.5 days on 8 GPUs. Previous state-of-the-art models were much slower and far more expensive to train.
What is more crucial, the architecture proved to be exceedingly adaptable. Researchers quickly discovered that you could use only the encoder part (giving models like BERT, which excel at understanding text), only the decoder part (giving models like GPT, which excel at generating text), or both together (giving models like BART and T5, which excel at translation and summarization).
Virtually all modern large language models (LLMs) are built on Transformer architecture. Models such as GPT-4, LLaMA, and Gemini use the decoder-only design, scaled to hundreds of billions of parameters.
7 The Big Picture
The Transformer solved two simultaneous problems in AI language modeling: it enabled training to be dramatically faster through parallelization, and it provided a much better way of understanding relationships between words, regardless of how far apart they appear in a sentence.
One paper, one architecture, and one idea that paying attention is all you really need changed the entire field of artificial intelligence. The models you interact with today are direct descendants of that 2017 breakthrough, grown larger, smarter, and more capable with every passing year.
Not bad for a network that does not even read in order.
References: Vaswani et al., “Attention Is All You Need,” NeurIPS 2017. Hugging Face Transformers Documentation.

